 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIRT2V: Training-Free Debiasing for Text-to-Video Diffusion Models
Jan 28, 2026Text-to-video (T2V) diffusion models have achieved rapid progress, yet their demographic biases, particularly gender bias, remain largely unexplored. We present FairT2V, a training-free debiasing framework for text-to-video generation that mitigates encoder-induced bias without finetuning. We first analyze demographic bias in T2V models and show that it primarily originates from pretrained text encoders, which encode implicit gender associations even for neutral prompts. We quantify this effect with a gender-leaning score that correlates with bias in generated videos. Based on this insight, FairT2V mitigates demographic bias by neutralizing prompt embeddings via anchor-based spherical geodesic transformations while preserving semantics. To maintain temporal coherence, we apply debiasing only during early identity-forming steps through a dynamic denoising schedule. We further propose a video-level fairness evaluation protocol combining VideoLLM-based reasoning with human verification. Experiments on the modern T2V model Open-Sora show that FairT2V substantially reduces demographic bias across occupations with minimal impact on video quality.
DeMark: A Query-Free Black-Box Attack on Deepfake Watermarking Defenses
Jan 23, 2026The rapid proliferation of realistic deepfakes has raised urgent concerns over their misuse, motivating the use of defensive watermarks in synthetic images for reliable detection and provenance tracking. However, this defense paradigm assumes such watermarks are inherently resistant to removal. We challenge this assumption with DeMark, a query-free black-box attack framework that targets defensive image watermarking schemes for deepfakes. DeMark exploits latent-space vulnerabilities in encoder-decoder watermarking models through a compressive sensing based sparsification process, suppressing watermark signals while preserving perceptual and structural realism appropriate for deepfakes. Across eight state-of-the-art watermarking schemes, DeMark reduces watermark detection accuracy from 100% to 32.9% on average while maintaining natural visual quality, outperforming existing attacks. We further evaluate three defense strategies, including image super resolution, sparse watermarking, and adversarial training, and find them largely ineffective. These results demonstrate that current encoder decoder watermarking schemes remain vulnerable to latent-space manipulations, underscoring the need for more robust watermarking methods to safeguard against deepfakes.
Robust CAPTCHA Using Audio Illusions in the Era of Large Language Models: from Evaluation to Advances
Jan 13, 2026CAPTCHAs are widely used by websites to block bots and spam by presenting challenges that are easy for humans but difficult for automated programs to solve. To improve accessibility, audio CAPTCHAs are designed to complement visual ones. However, the robustness of audio CAPTCHAs against advanced Large Audio Language Models (LALMs) and Automatic Speech Recognition (ASR) models remains unclear. In this paper, we introduce AI-CAPTCHA, a unified framework that offers (i) an evaluation framework, ACEval, which includes advanced LALM- and ASR-based solvers, and (ii) a novel audio CAPTCHA approach, IllusionAudio, leveraging audio illusions. Through extensive evaluations of seven widely deployed audio CAPTCHAs, we show that most existing methods can be solved with high success rates by advanced LALMs and ASR models, exposing critical security weaknesses. To address these vulnerabilities, we design a new audio CAPTCHA approach, IllusionAudio, which exploits perceptual illusion cues rooted in human auditory mechanisms. Extensive experiments demonstrate that our method defeats all tested LALM- and ASR-based attacks while achieving a 100% human pass rate, significantly outperforming existing audio CAPTCHA methods.
Help or Hurdle? Rethinking Model Context Protocol-Augmented Large Language Models
Aug 18, 2025The Model Context Protocol (MCP) enables large language models (LLMs) to access external resources on demand. While commonly assumed to enhance performance, how LLMs actually leverage this capability remains poorly understood. We introduce MCPGAUGE, the first comprehensive evaluation framework for probing LLM-MCP interactions along four key dimensions: proactivity (self-initiated tool use), compliance (adherence to tool-use instructions), effectiveness (task performance post-integration), and overhead (computational cost incurred). MCPGAUGE comprises a 160-prompt suite and 25 datasets spanning knowledge comprehension, general reasoning, and code generation. Our large-scale evaluation, spanning six commercial LLMs, 30 MCP tool suites, and both one- and two-turn interaction settings, comprises around 20,000 API calls and over USD 6,000 in computational cost. This comprehensive study reveals four key findings that challenge prevailing assumptions about the effectiveness of MCP integration. These insights highlight critical limitations in current AI-tool integration and position MCPGAUGE as a principled benchmark for advancing controllable, tool-augmented LLMs.
Fusion-Catalyzed Pruning for Optimizing Deep Learning on Intelligent Edge Devices
Oct 30, 2020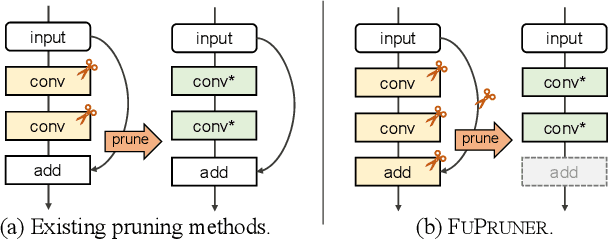
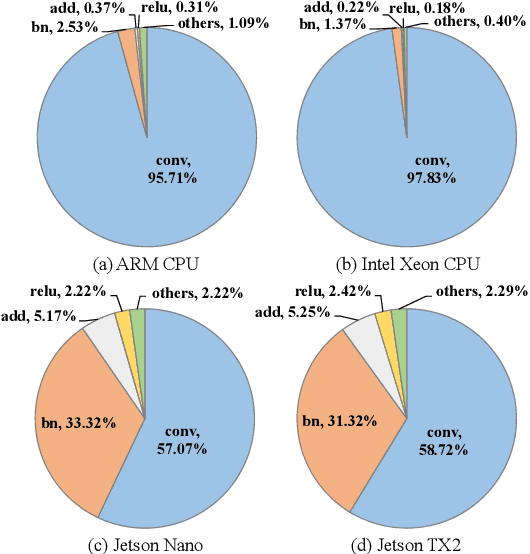
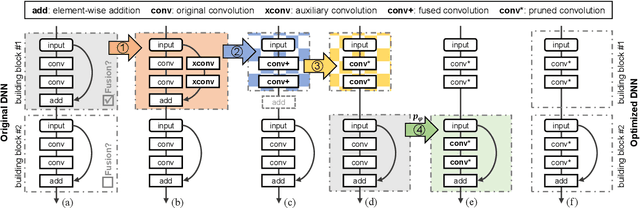
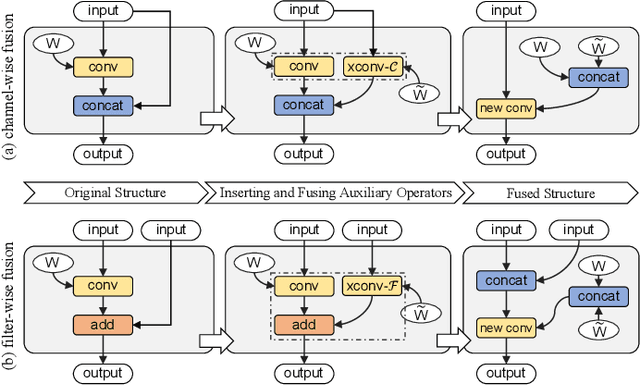
The increasing computational cost of deep neural network models limits the applicability of intelligent applications on resource-constrained edge devices. While a number of neural network pruning methods have been proposed to compress the models, prevailing approaches focus only on parametric operators (e.g., convolution), which may miss optimization opportunities. In this paper, we present a novel fusion-catalyzed pruning approach, called FuPruner, which simultaneously optimizes the parametric and non-parametric operators for accelerating neural networks. We introduce an aggressive fusion method to equivalently transform a model, which extends the optimization space of pruning and enables non-parametric operators to be pruned in a similar manner as parametric operators, and a dynamic filter pruning method is applied to decrease the computational cost of models while retaining the accuracy requirement. Moreover, FuPruner provides configurable optimization options for controlling fusion and pruning, allowing much more flexible performance-accuracy trade-offs to be made. Evaluation with state-of-the-art residual neural networks on five representative intelligent edge platforms, Jetson TX2, Jetson Nano, Edge TPU, NCS, and NCS2, demonstrates the effectiveness of our approach, which can accelerate the inference of models on CIFAR-10 and ImageNet datasets.